你是否曾在使用AI聊天机器人时,注意到屏幕下方显示的“消耗XX Token”?又或者在查阅技术文档时,反复看到“上下文窗口为128K Token”这样的描述?这些神秘的“Token”究竟是什么?它们为何能成为衡量AI能力、成本乃至时代价值的通用尺度?
本文将带你系统性地揭开Token的神秘面纱。我们将从其基本概念出发,深入解析编码原理,并以DeepSeek、Qwen等主流大模型为例,剖析其Token设计的精妙之处。通过图文结合的方式,让抽象的技术变得清晰可见,帮助你建立对大模型底层工作机制的坚实认知。
引言:当我们在说“Token”时,我们到底在说什么?
在日常与AI的互动中,“Token”一词已无处不在。它不仅是后台计费的单位,更是决定AI“记忆力”和“思考速度”的核心参数。然而,当我们追问其本质时,许多人却难以给出清晰的定义。
一个Token既不是一个简单的字符,也不完全等同于一个单词。它可以是“我”、“爱”这样的单字,也可以是“人工智能”这样的复合词,甚至可能是代码中的符号“{”。它的边界由一种名为“分词器(Tokenizer)”的算法决定,而非人类的语言直觉。
因此,要真正驾驭AI,我们必须首先理解Token。这不仅仅是学习一个术语,而是掌握一把钥匙——一把能够打开大模型内部世界大门的钥匙。本文的目标,就是为你提供这样一套完整的认知框架,让你不仅能说出“什么是Token”,更能理解它为何如此重要。
第一部分:Token的本质——大模型的“文字积木”
想象一下,当你向AI提问时,它并不会像人一样直接阅读整段文字。相反,它会先将你的问题拆解成无数个微小的碎片,然后逐一分析、处理,最后再将结果拼接起来,形成回答。这些被拆解出的最小单元,就是Token。
官方中文译名“词元”精准地概括了其内涵:“词”代表其作为语言元素的属性,“元”则强调了其作为基础构成单元的地位。你可以将其类比为乐高积木:自然语言是最终建成的宏伟城堡,而每一个Token,就是组成这座城堡的一块块独立积木。
这种拆解过程至关重要,因为大模型本质上是一个庞大的数学计算系统,它无法直接处理“语义”,只能处理数字。因此,每个Token都会被映射到一个唯一的数字ID,这个ID就像是积木上的编号。模型通过对这些数字序列进行复杂的运算,来模拟对语言的理解和生成。
需要特别注意的是,Token与字符或单词有着本质区别。一个汉字通常对应一个Token,但并非绝对。例如,在英文中,长单词“unhappiness”常被拆分为["un", "happiness"]两个Token;而在中文里,高频词“人工智能”可能被保留为一个整体Token,也可能被拆分为["人工", "智能"]。这一切都取决于分词器的规则,而非固定的语法。小结:Token是大模型处理语言的最小离散单元,是连接人类语言与机器计算的桥梁。
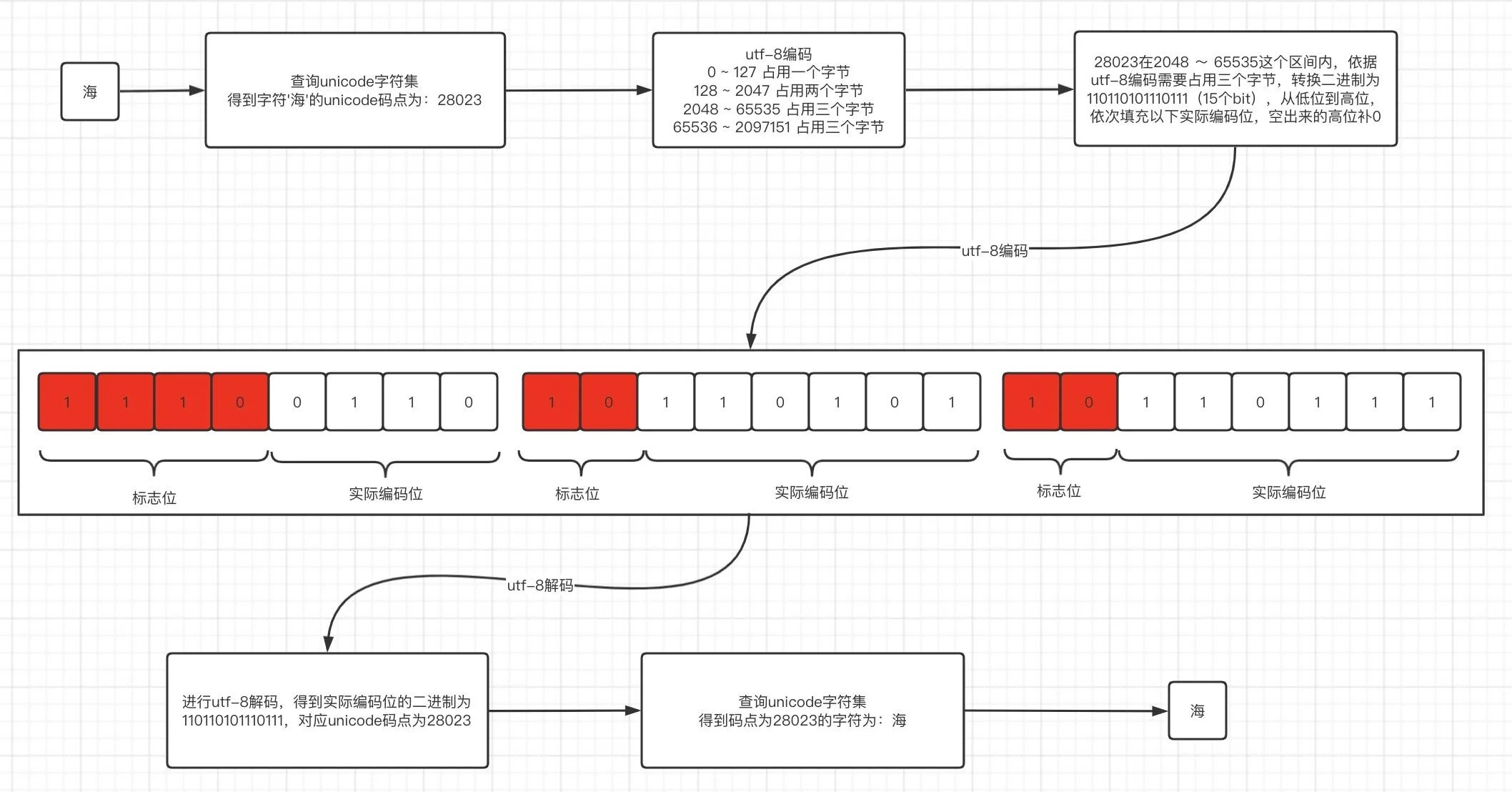
第二部分:编码原理揭秘——从文本到数字序列的旅程
既然Token是模型的“食物”,那么“烹饪”这道菜的第一步,就是准备食材。这个过程的核心执行者,便是分词器(Tokenizer)。它负责将原始文本一步步转化为模型可以消化的数字序列。
整个流程可以分解为四个关键步骤:
1. 预处理:对输入文本进行清洗和标准化,例如统一Unicode编码、处理特殊空格等。
2. 子词切分:这是最核心的一步,即应用特定算法将文本切分成Token序列。
3. ID映射:根据模型内置的词汇表(Vocabulary),将每个Token转换为其对应的唯一整数ID。
4. 嵌入表示:模型通过嵌入层,将这些ID转换为高维向量,这些向量承载着丰富的语义信息,供后续的Transformer架构进行深度处理。
在众多子词切分算法中,BPE(字节对编码,Byte Pair Encoding) 是目前最主流的技术之一。其核心思想非常直观:从最基本的字符(或字节)开始,反复寻找并合并数据集中出现频率最高的相邻字符对,从而逐步构建出一个包含常见子词和完整词的高效词汇表。
BPE算法原理图:展示字节对编码的迭代合并过程
图注:该图展示了字节对编码(BPE)的迭代合并过程。左侧为初始状态,每个字符都是独立的单元。中间部分演示了如何统计相邻字符对的频率,并选择最高频的组合(如"l"和"o")进行合并。右侧展示了经过多次合并后形成的更长的子词单元,最终构成了一个高效的词汇表。此图生动地解释了BPE算法如何通过“贪心”策略,从简单字符构建出复杂词元。
除了BPE,还有两种重要的算法:WordPiece(BERT系列采用,基于概率最大化原则进行合并)和SentencePiece(T5、Llama系列采用,不依赖空格分词,更适合多语言)。尽管细节不同,但它们的目标一致:在保持词汇表大小可控的同时,最大限度地减少未登录词(OOV)问题,并提升对新词和罕见词的泛化能力。小结:BPE等子词分词算法通过统计规律,将文本高效地压缩为最优的Token序列,是大模型理解语言的基础。
第三部分:Token的核心作用——不只是计费单位
Token的重要性远超其作为API计费单位的角色。它在性能、记忆和成本三个维度上,深刻影响着大模型的能力边界。
在性能维度上,Token的数量直接决定了计算量。模型处理一个包含1000个Token的提示,所需的时间和算力远超处理一个100个Token的提示。这是因为Transformer模型的核心注意力机制,其计算复杂度大致与Token数量的平方成正比。这意味着,输入长度翻倍,计算量可能增加四倍。
在记忆维度上,Token定义了模型的“上下文窗口”(Context Window)。这相当于模型的短期记忆容量,决定了它能记住多少历史对话或参考多少篇幅的文档。当前主流模型的上下文长度差异巨大:
- GPT-4 Turbo: 128K Token
- Claude 3 Opus: 200K Token
- Gemini 1.5 Pro: 高达1M Token
图注:该图用堆叠的书本形象地对比了不同大模型的上下文长度。GPT-4的128K Token约等于半本《三体》,Claude 3的200K Token接近一本,而Gemini 1.5 Pro的1M Token则高达五本之多。此图直观地说明了,拥有更大上下文窗口的模型,能够一次性处理和理解更长、更复杂的文本,这对于撰写长篇报告、分析整本代码库或进行多轮深度对话至关重要。
在成本维度上,商业API普遍按输入和输出的Token总数收费。一次问答的成本,就是输入Prompt的Token费用加上模型生成回复的Token费用。有趣的是,由于编码效率的差异,中文用户往往比英文用户更“省”。粗略估算,1000个Token大约对应750个英文单词,但能表达500-700个汉字。这是因为英文长词常被拆分,而中文高频词组常被合并为单个Token,从而提升了信息密度和性价比。小结:Token是衡量大模型能力的三大标尺:它既是计算的燃料,也是记忆的容器,更是经济的货币。
第四部分:主流模型实战——DeepSeek与Qwen的Tokenizer设计探秘
让我们将目光聚焦于两款备受关注的国产大模型:DeepSeek与Qwen,通过具体实例,探究其Tokenizer设计的独特之处。
DeepSeek模型分析
DeepSeek系列模型采用了BBPE(字节级BPE) 算法。这种方法将文本首先转换为UTF-8字节流,然后在字节级别上执行BPE合并。其词汇表规模约为129,280个Token。这种设计的最大优势在于其普适性:任何字符,无论是生僻汉字、Emoji还是编程符号,都能被分解为字节,从而避免了“未知词”问题。其处理策略遵循“高频词整体保留,低频词拆分为子词”的原则,确保了编码的高效性。
Qwen(通义千问)模型分析
同样采用BBPE算法的Qwen,展现了另一番景象。其词汇表更为庞大,达到了约15万+的规模。这一设计使其在中文处理上表现出色,平均1个Token可表示约1.3–1.8个汉字,极大地提升了中文文本的压缩效率。此外,Qwen的Tokenizer对代码符号有良好的支持,并且原生支持多语言混合输入,使其在国际化场景下更具优势。
对比总结
两者均采用先进的BBPE算法,体现了对多语言和复杂符号处理的重视。共性在于都通过字节级处理解决了OOV问题。差异则体现在词汇表规模和优化侧重上:DeepSeek的词汇表相对紧凑,追求通用性和效率;而Qwen则通过更大的词汇表,对中文进行了深度优化,力求在母语场景下达到最佳的表达效率。小结:DeepSeek与Qwen的Tokenizer设计,反映了在通用性与领域专精之间的不同权衡,共同推动了中文大模型的发展。
结语:理解Token,就是理解AI时代的经济学
综上所述,Token绝非一个简单的技术指标。它是大模型世界的“通用货币”,扮演着三重关键角色:作为理解单元,它是AI“读懂”人类语言的基本粒子;作为记忆载体,它定义了模型的认知疆界;作为经济度量,它量化了每一次智能服务的真实成本。
黄仁勋曾预言:“未来的数据中心,就是生产Token的工厂。” 这句话深刻地揭示了AI产业的价值逻辑。谁能在单位电力和算力下,更高效地生产高质量的Token,谁就能在AI时代赢得竞争优势。
因此,对于每一位高校师生而言,培养“Token意识”至关重要。在使用AI工具时,学会提出简洁、精准的问题,不仅能让交流更高效,也能在无形中节约资源。更重要的是,理解Token背后的原理,是迈向更深层次探索大模型技术的第一步。未来,随着多模态技术的发展,Token的概念将进一步扩展至图像、音频等领域,成为连接所有智能形态的通用接口。现在,就让我们从理解这枚小小的“词元”开始,共同迎接这个由Token驱动的智能新时代。



